Bio: I joined NVIDIA as an engineer in 2023. Before that, I received my Ph.D. in computer applied technology at Peking University, China, in 2023, and I received the B.E. degree from the School of Computer Science, Beijing University of Posts and Telecommunications, China, in 2018.
Research: I am excited about developing deep models with hand-designed and automated search methods to solve computer vision challenges. Currently, my research focuses on learning 2D and 3D representations of objects and scenes towards improving accuracy and robustness of perception tasks in complex environments. Outside my research, I love drawing, swimming, and reading literature.
selected publications
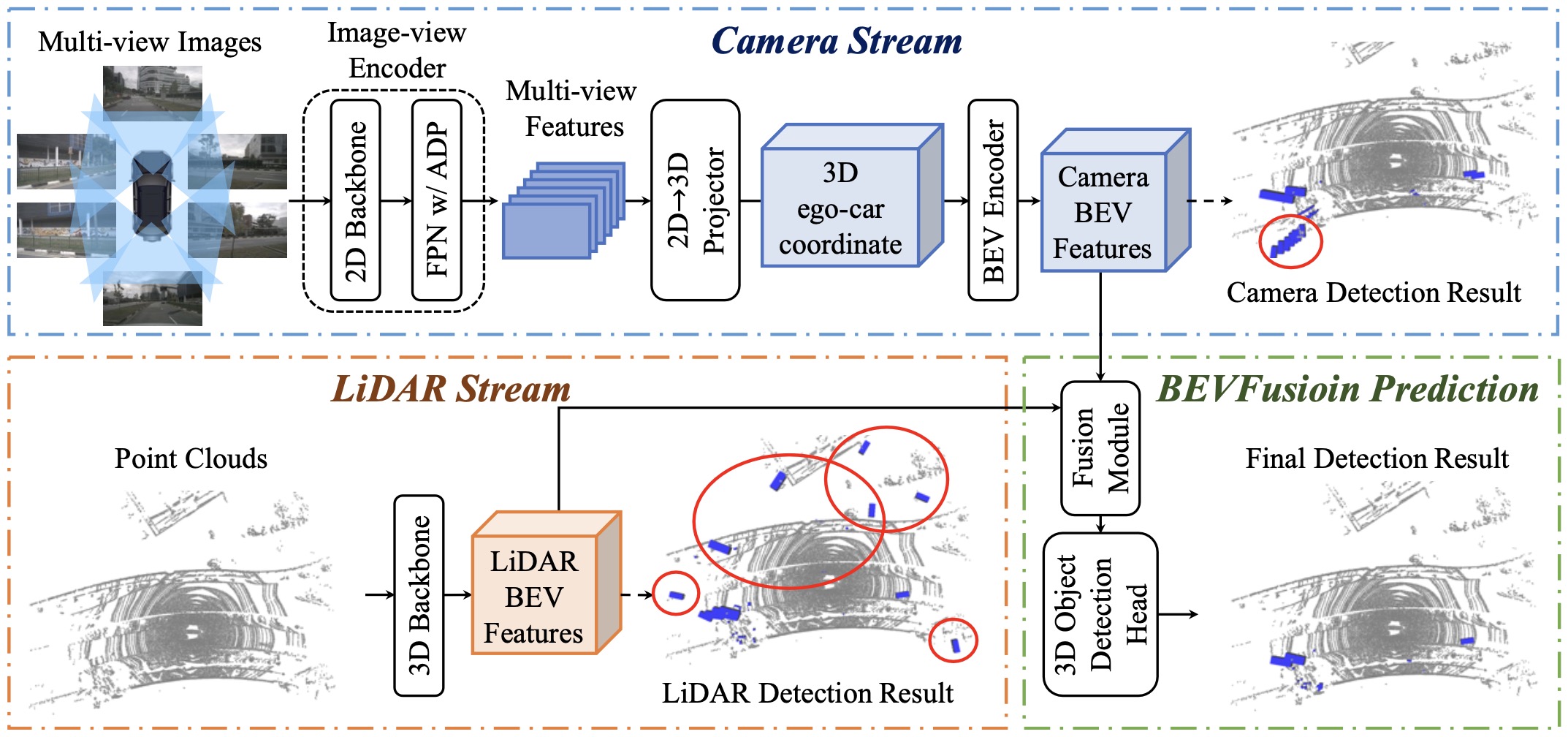
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
Tingting Liang, Hongwei Xie, Kaicheng Yu, and 6 more authors
In Neural Information Processing Systems (NeurIPS), 2022
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discovered that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure.
@inproceedings{liang2022bevfusion,title={{BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework}},author={Liang, Tingting and Xie, Hongwei and Yu, Kaicheng and Xia, Zhongyu and Lin, Zhiwei and Wang, Yongtao and Tang, Tao and Wang, Bing and Tang, Zhi},booktitle={{Neural Information Processing Systems (NeurIPS)}},year={2022},}
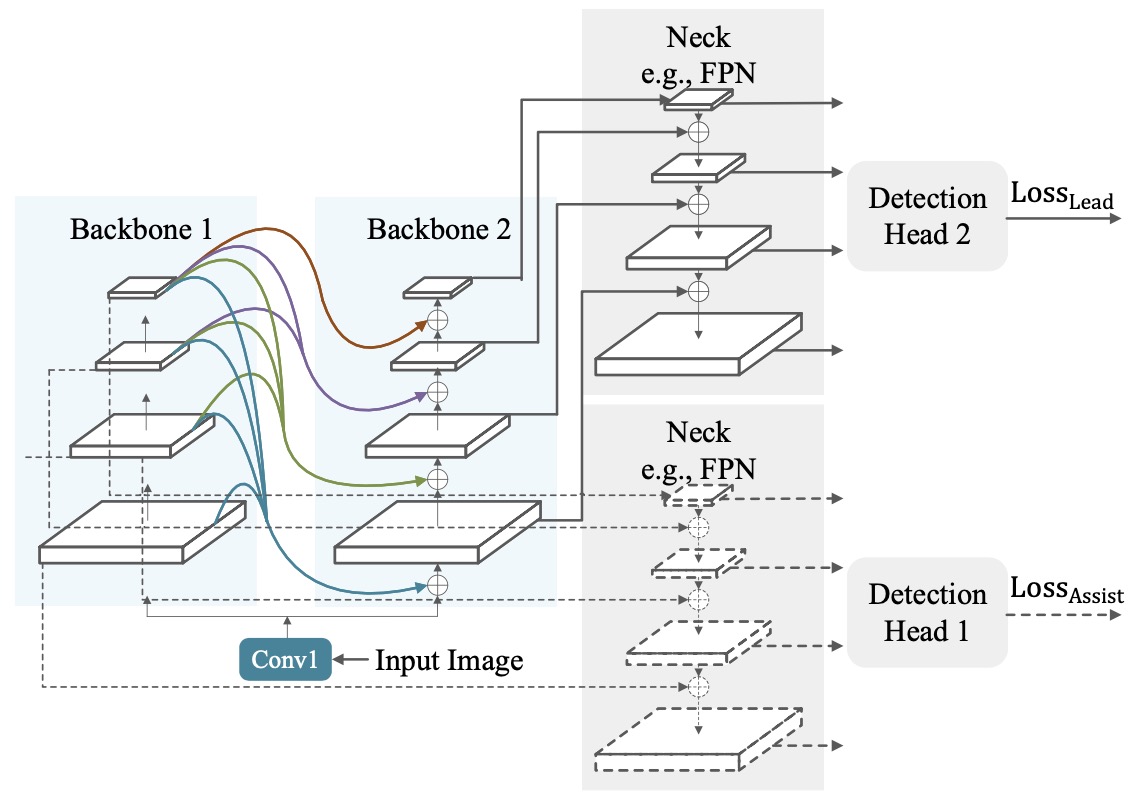
CBNet: A Composite Backbone Network Architecture for Object Detection
Ting-Ting Liang, Xiaojie Chu, Yudong Liu, and 5 more authors
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely , to construct high-performance detectors using existing open-source pre-trained backbones under the pre-training fine-tuning paradigm. In particular, architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple identical backbone networks and gradually expands the receptive field to more effectively perform object detection. We also propose a better training strategy with auxiliary supervision for CBNet-based detectors. CBNet has strong generalization capabilities for different backbones and head designs of the detector architecture. Without additional pre-training of the composite backbone, CBNet can be adapted to various backbones (i.e., CNN-based vs. Transformer-based) and head designs of most mainstream detectors (i.e., one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNet introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our CB-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which are significantly better than the state-of-the-art results (i.e., 57.7% box AP and 50.2% mask AP) achieved by Swin-L, while reducing the training time by 6x. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data.
@article{DBLP:journals/tip/LiangCLWTCCL22,author={Liang, Ting{-}Ting and Chu, Xiaojie and Liu, Yudong and Wang, Yongtao and Tang, Zhi and Chu, Wei and Chen, Jingdong and Ling, Haibin},title={CBNet: {A} Composite Backbone Network Architecture for Object Detection},journal={{IEEE Transactions on Image Processing (TIP)}},volume={31},pages={6893--6906},year={2022},url={https://doi.org/10.1109/TIP.2022.3216771},doi={10.1109/TIP.2022.3216771},timestamp={Mon, 05 Dec 2022 13:33:25 +0100},biburl={https://dblp.org/rec/journals/tip/LiangCLWTCCL22.bib},bibsource={dblp computer science bibliography, https://dblp.org},}
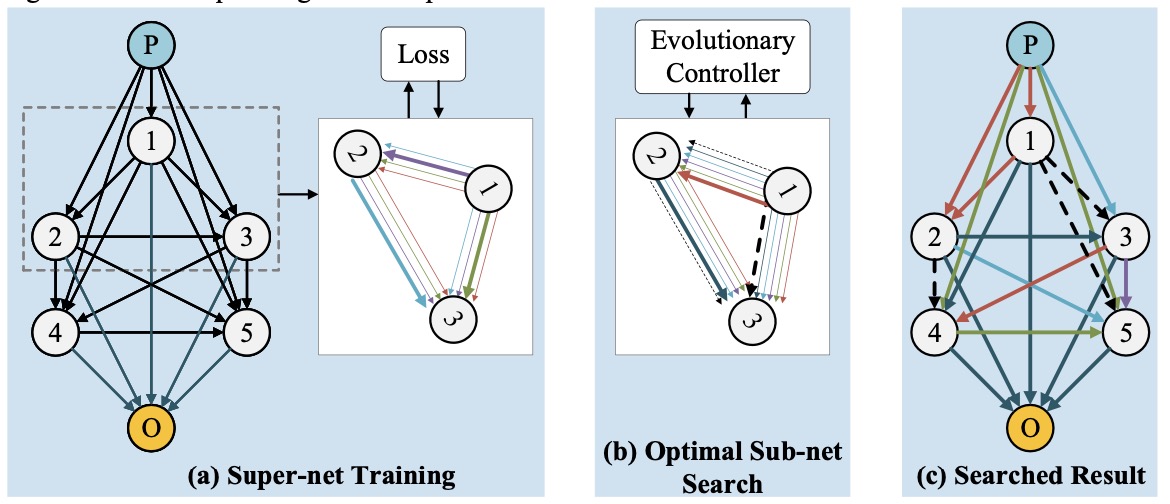
OPANAS: One-Shot Path Aggregation Network Architecture Search for Object Detection
Tingting Liang, Yongtao Wang, Zhi Tang, and 2 more authors
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Recently, neural architecture search (NAS) has been exploited to design feature pyramid networks (FPNs) and achieved promising results for visual object detection. Encouraged by the success, we propose One-Shot Path Aggregation Network Architecture Search (OPANAS) algorithm, which significantly improves both searching efficiency and detection accuracy. Specifically, we first introduce six heterogeneous information paths to build our search space, namely top-down, bottom-up, fusing-splitting, scale-equalizing, skip-connect and none. Second, we propose a novel search space of FPNs, in which each FPN candidate is represented by a densely-connected directed acyclic graph (each node is a feature pyramid and each edge is one of the six heterogeneous information paths). Third, we propose an efficient one-shot search method to find the optimal path aggregation architecture, that is, we first train a super-net and then find the optimal candidate with an evolutionary algorithm. Experimental results demonstrate the efficacy of the proposed OPANAS for object detection: (1) OPANAS is more efficient than state-of-the-art methods (i.e., NAS-FPN and Auto-FPN), at significantly smaller searching cost (i.e., only 4 GPU days on MS-COCO); (2) the optimal architecture found by OPANAS significantly improves main-stream detectors including RetinaNet, Faster R-CNN and Cascade R-CNN, by 2.3 3.2 % mAP comparing to their FPN counterparts; and (3) a new state-of-the-art accuracy-speed trade-off (52.2 % mAP at 7.6 FPS) at smaller training costs than comparable state-of-the-arts.
@inproceedings{DBLP:conf/cvpr/LiangWTHL21,author={Liang, Tingting and Wang, Yongtao and Tang, Zhi and Hu, Guosheng and Ling, Haibin},title={{OPANAS:} One-Shot Path Aggregation Network Architecture Search for
Object Detection},booktitle={{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},pages={10195--10203},publisher={Computer Vision Foundation / {IEEE}},year={2021},doi={10.1109/CVPR46437.2021.01006},timestamp={Mon, 18 Jul 2022 16:47:41 +0200},biburl={https://dblp.org/rec/conf/cvpr/LiangWTHL21.bib},bibsource={dblp computer science bibliography, https://dblp.org},}
For more publications, please refer to publications! Contact: tingtingliang AT pku.edu.cn