BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
NeurIPS 2022
Why multi-sensor for perception?

LiDAR and camera technology are essential for enabling self-driving cars to navigate their surroundings. However, these systems have their own limitations. Cameras provide detailed visual information, but can be affected by weather and do not offer reliable 3D data. LiDAR, on the other hand, provides 3D information but can struggle to accurately measure objects that are far away or are dark in color, as they absorb NIR (Near Infrared) radiation. As a result, relying solely on either LiDAR or camera data can lead to failures in complex scenarios.
How to fuse information from multi-sensors?
In the early stage of perception systems, people design separate deep models for each sensor and fuse information via post-processing approaches. This method is limited by the loss of intermediate information. Recently, people have designed LiDAR-camera fusion deep networks to better leverage information from both modalities. Specifically, the majority of works can be summarized as follow: i) given one or a few points of the LiDAR point cloud, LiDAR to world transformation matrix and the essential matrix (camera to world); ii) people transform the LiDAR points or proposals into camera world and use them as queries, to select corresponding image features. This line of work constitutes the state-of-the-art methods of 3D perception.
However, one underlying assumption that people overlooked is, that as one needs to generate image queries from LiDAR points, the current LiDAR-camera fusion methods intrinsically depend on the raw point cloud of the LiDAR sensor. In the realistic world, people discover that if the LiDAR sensor input is missing, for example, LiDAR points reflection rate is low due to object texture, a system glitch of internal data transfer, or even the field of view of the LiDAR sensor cannot reach 360 degrees due to hardware limitations, and current fusion methods fail to produce meaningful results. This fundamentally hinders the applicability of this line of work in the realistic autonomous driving system.

We argue the ideal framework for LiDAR-camera fusion should be, that each model for a single modality should not fail regardless of the existence of the other modality, yet having both modalities will further boost the perception accuracy.
Our method
To this end, we propose a surprisingly simple yet effective framework that disentangles the LiDAR-camera fusion dependency of the current methods, dubbed BEVFusion. Specifically, our framework has two independent streams that encode the raw inputs from the camera and LiDAR sensors into features within the same BEV space (Why BEV? People have discovered that bird’s eye view (BEV) has been an de-facto standard for autonomous driving scenarios as, generally speaking, car cannot fly). We then design a simple module to fuse these BEV-level features after these two streams, so that the final feature can be passed into modern task prediction head architecture.

As our framework is a general approach, we can incorporate current single modality BEV models for camera and LiDAR into our framework. We moderately adopt Lift-Splat-Shoot as our camera stream, which projects multi-view image features to the 3D ego-car coordinate features to generate the camera BEV feature. Similarly, for the LiDAR stream, we select three popular models, two voxel-based ones and a pillar-based one to encode the LiDAR feature into the BEV space.
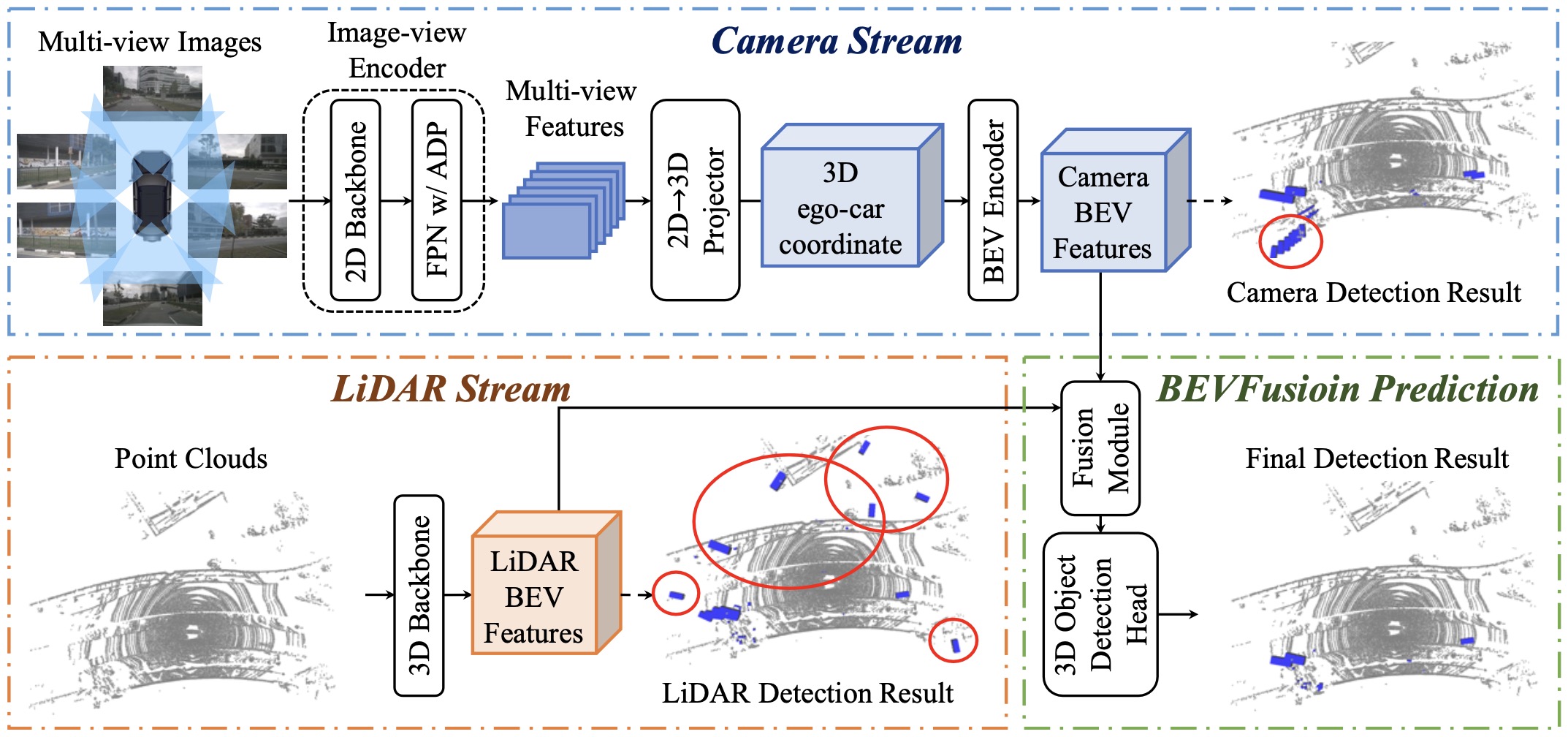
Results
On the nuScenes dataset, our simple framework shows great generalization ability. Following the same training settings, BEVFusion improves PointPillars and CenterPoint by 18.4% and 7.1% in mean average precision (mAP) respectively, and achieves a superior performance of 69.2% mAP comparing to 68.9% mAP of TransFusion, which is considered as state-of-the-art. Under the robust setting by randomly dropping the LiDAR points inside object bounding boxes with a probability of 0.5, we propose a novel augmentation technique and show that our framework surpasses all baselines significantly by a margin of 15.7%~28.9% mAP and demonstrate the robustness of our approach.

Overview Video

Concurrent works
Some concurrent works also focus on fusing LiDAR-camera in 3D space:
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. MIT HAN Lab
FUTR3D: A Unified Sensor Fusion Framework for 3D Detection. Tsinghua MARS Lab
Further Information
To learn more about work, watch our video in NeurIPS2022.
For more detailed information, check out our paper and code. We are happy to receive your feedback!
@inproceedings{liang2022bevfusion,
title = {BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework},
author = {Liang, Tingting and Xie, Hongwei and Yu, Kaicheng and Xia, Zhongyu and Lin, Zhiwei and Wang, Yongtao and Tang, Tao and Wang, Bing and Tang, Zhi},
booktitle = {Neural Information Processing Systems (NeurIPS)},
year = {2022},
}